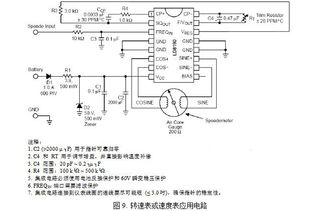
CS8190和LD8190是專為空心轉速表(如汽車儀表盤中的轉速表)設計的驅動器集成電路,采用SOP20(Small Outline Package,20引腳)封裝。這類集成電路在現代工業和汽車電子中扮演著關鍵角色,主要用于精確控制轉速表的指針運動,將電信號轉換為可見的機械指示。
在功能上,CS8190和LD8190集成電路接收來自傳感器(如曲軸位置傳感器)的脈沖信號,經過內部處理(如信號放大、濾波和驅動電路)后,輸出適當的電流或電壓驅動步進電機或模擬指針機構。其設計注重高精度和穩定性,確保轉速表在各種條件下(如溫度變化或電壓波動)都能準確響應。SOP20封裝使得這些芯片體積小巧,易于集成到緊湊的電子系統中,同時提供良好的散熱和電氣性能。
應用領域廣泛,不僅限于汽車行業,還包括工業機械、航空航天和家用電器等需要轉速監控的場景。例如,在汽車中,它們幫助駕駛員實時監控發動機轉速,預防過載;在工業設備中,可用于監測電機或渦輪機的運行狀態。使用這些集成電路時,需注意電源電壓匹配(通常為5V或12V)、信號輸入范圍以及環境溫度限制,以避免損壞。
CS8190和LD8190 SOP20空心轉速表驅動器集成電路是高效、可靠的解決方案,通過先進的技術提升了轉速表的性能和壽命。隨著電子技術的進步,未來這類芯片可能集成更多智能功能,如自診斷和通信接口,進一步拓展其應用前景。









